
The PhD Metagame
Don't Make Things Actually Work
It's a trap!
Research papers generally target a specific advancement on some axis. A laser-focused algorithm, model, framing, benchmark, or analysis.
But in fields like computer science, your research is temptingly adjacent to making a working, useful system. A robot that can assist with dishwashing. Video captioning from which a blind person can reliably cook a recipe. Widespread adoption of your open-source visualization software, database, software correctness checker, or packet-routing algorithm.
If you have a burning desire to make useful things, this adjacency will drive you mad.
The problem is, this gap that sits between your research and actually useful systems, while seemingly so narrow, actually holds hundreds of hours of “engineering” work that will stunt your research progress.
Let’s look at an example with a Sun Horizontal tomato.
Case Study: The Sun Horizontal Tomato
Check out the Figure 1 from the ACL 2021 paper, Hierarchical Context-aware Network for Dense Video Event Captioning:01
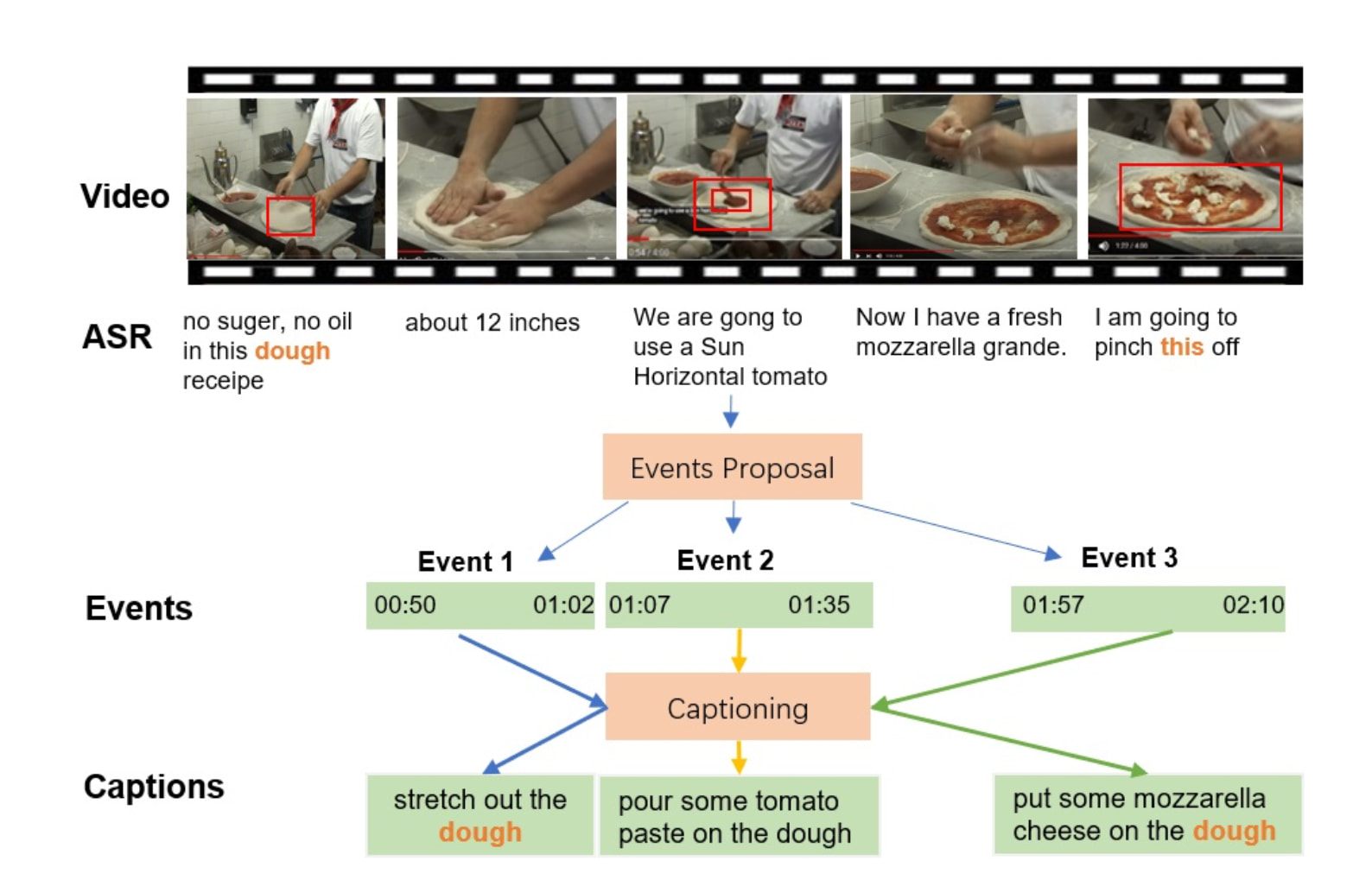
Caption from the authors: "A showcase of dense video event captioning. Given a video and the speech text, the task is to generate event proposals and captions."
The point of this figure is that the model produces video captions (bottom), including references to previous words like “dough.”
But if you’ve ever made pizza, you’ll recognize that the descrptions are comically wrong:
-
The speech recognition (ASR) transcribes “a Sun Horizontal tomato”
- this should be “San Marzano,” a tomato famous for its use in sauces
-
The resulting caption says to use “pour tomato paste”
- spreading, not just pouring, is critical
- even more importantly, tomato paste is a completely separate ingredient. It’s extremely thick and concentrated. What’s actually being used here is a sauce made from San Marzano tomatoes
-
put cheese on the dough
- if I was describing this to a human, I’d say to put cheese on the sauce, not the dough. The only exposed bits of the dough are the crust (cheesy crust?)
These caption errors are so glaring, and the pizza they’d produce if followed literally would be so wrong, you’d think the authors would be working to correct them, right? Or, at the very least, they’d discuss them? Or even mention them?
Nope! None of these problems are mentioned by the authors in their caption or the running text.
Such errors are surprising because Figure 1s have an unwritten acknowledgement that they can be cherry-picked or even hand-written by the authors, unless the promise “random model-generated examples” is written.
But what might surprise you even more is that the authors made the correct decision to omit discussion of the mistakes in Figure 1. That is because their paper does not focus on fixing those mistakes. (In fact, their paper creates those mistakes.)
The Bait: Fix The Mistakes
Say you want the video captions to actually be correct. When do you start tackling the myriad challenges that emerge?
Here, the underlying problems are:
- better automatic speech recognition (ASR) (“San Marzano”)
- better object recognition (subcomponents of pizza)
- better image captions (“spread” not just “pour”)
- correctly merging ASR with object recognition and image captions (“San Marzano sauce”, not “tomato paste;” put cheese on “sauce” not “dough”)
If you’re working on just one of those problems, like object recognition, that alone would be a good project.02 But if you’re working on a higher level task like this, improving your object recognizer is hopelessly out-of-scope.
If those are the systems you’re working with, then to make a truly useful video description model,03 you’ll end up solving a million instances of lower-level problems like:
- word sense disambiguation (e.g., “clip” = a tie, a segment, to attach, to cut)04
- reliably knowing who people are (e.g., how many people in video? who is who in each frame? is anyone famous / known?)
- inferring a much wider variety of multi-part objects and actions than your off-the-shelf models (really, their datasets) support
- object permanence and transformations across time
If your system involves machine learning, you’ll need to pour enormous time into the AI/HCI bridge: how do people still use the system fully when it fails? Even if it’s 99% accurate,05 if it’s used tens of thousands of times, there will be hundreds of failures. In ML research, we avoid this problem entirely. In real life, you can’t.
Even if you do all that, you must then spend hundreds of hours on problems that are considered “solved:”06 the good old engineering work of building something. It takes companies piles of programmer-months to make a useful application or (god forbid) physical device. Design work, wrestling with platform APIs, data management, user testing, the whole nine yards.
Many Students Take the Bait
Robotics PhD students in particular seem to fall into this trap. Somewhere roughly around year 3, they’ve gotten a hang of the field in general — published a couple papers, gone to conferences, know what’s going on and what’s out there.
But something has started bothering them. All their experiments are in isolation. And they have this cool, rare, space-age tech right in front of them (the robot) that seems so close to actually doing all kinds of neat helpful little things. But it’s just not quite integrated enough.
So they go off and flounder around for months or years trying to get the robot to do useful things, and spend lots of time on what we call ✨ engineering ✨ (i.e., not science),07 and finally maybe a couple things kind of work, but they realize, oh god, I have to get back to actual research.
Maybe this is inevitable. I certainly had a phase like this of my PhD where I wanted to “do things properly:”
- get familiar with a bunch of basic linguistics I didn’t need to
- really understand the fundamentals of math I didn’t need to know
- make nice websites with demos and dataset browsers
I think it’s OK to go off and do this a little bit. At least in the USA, the PhD is so long, and you got in it because of some degree of true passion and curiosity, it may be soul-fulfilling to pursue it. There’s a chance it’s informative, too. Usually, you discover there’s no boogeyman under the bed.08
Don’t Take the Bait
But you should largely resist the urge to make truly working, useful systems. Unless you can scope a specific class of problems into an interesting research project, these quests for quality are a waste of time because they cause gaps in your publication efforts. They’re a weaker strategy in the PhD metagame. Students who resist them are more successful.
This is difficult in practice if your brain works a certain way. At least for me, a huge part of training my instincts as a researcher was resisting the temptation to fix individual problems or build useful things.
For machine learning specifically, the reason is The Bitter Lesson: if you just sit back and use more data, many problems simply go away. As soon as you start mucking with things given your human knowledge and expectations, you’ll start handcrafting brittle expectations into your systems. You may be able to iron out a handful of cases, but you will blind yourself from the 10x or 100x improvements in the underlying machine learning paradigm.09
In general, I think it’s about identifying the proper topic and scope of a research paper. The science community cares about certain kinds of problems, and looks down on other kinds of work.10 If you go off and do work that has the flavor of “fixing many little problems,” it’s usually hard to write about in a paper, which means it’s not useful science fodder.
Postscript
When I’d first read the Sun Horizontal paper, I was appalled at all the unacknowledged mistakes in Figure 1. I wished—and still wish—they even mentioned the errors, because it felt like we weren’t setting our sights high enough. That was 2021.
It’s now 2025. We now have better ASR models, and extraordinarily better image caption models with multimodal LLMs. If you’d worked on the above individual problems, all of your work would now be irrelevant, because newer models solve so much of it and make slightly different mistakes.
The paper’s authors made the right call to publish, warts and all. They did the best they could with the models they had, including all the limitations. They got a research paper out of it, and furthered their careers.11
Now that the science clock has made another turn, everything is new again. Are the latest models still stuck pouring tomato paste onto pizzas? Or are we finally graced with San Marzano-based sauce, spread in neat circular patterns across the top of the dough?
Footnotes
Ji and Guo et al., 2021; https://aclanthology.org/2021.acl-long.156.pdf ↩︎
In fact, “just make a better object recognizer” might still be too big a project! (Depending on what year it is.) You might focus on a subset of object recognition. ↩︎
I.e., that works across more videos than just pizza. ↩︎
This one less-so these days with excellent language models given sufficient context. ↩︎
Quite optimistic ↩︎
Academic for “boring” ↩︎
The usual: can the robot know and remember where it is? Can it reliably identify objects and people around it? Can it carry out simple tasks like picking up and handing objects? In real time? Can it perform multi-step tasks like clearing a table? Say bye bye to several years. ↩︎
I.e., there’s no magic or big secrets, just some math or engineering details. ↩︎
The tricky thing about larger trends like The Bitter Lesson in practice is that their time span is larger than your PhD. You may be working right at an inflection point where you have the resources (i.e., data collection, compute) to harness it. But you easily might not be. Either way, you need to publish regularly. ↩︎
One funny thing you start to get the flavor of is what this kind of “integration” work looks like. Two categories I can think of are survey papers (usually in journals, not conferences) and robot task competitions (e.g., real robots go through real house and try to accomplish a set of goals). Top-tier researchers avoid these kinds of projects. ↩︎
A positive way of looking at the paper itself is that it’s a snapshot in time of how good our systems were at each task (ASR, captioning, etc.). ↩︎
