Electron Breaks Brain
Trying to get Electron setup has made me realize I don’t understand so many aspects of my build and deploy and hosting setup.
Showing anything
I will just let my comments speak for themselves right now rather than try to re-type out the long story of my confusions and failures.
// mainWindow.loadFile("dist/index.html"); // doesn't work (can't find rest)
// mainWindow.loadURL("http://localhost:5173/play"); // works, though requires dev server
// mainWindow.loadFile("index.html"); // doesn't work (uses top-level index.html, even if this file (main.js) is in dist/)
// mainWindow.loadURL(`file://${import.meta.dirname}/dist/index.html`); // doesn't fix it.
// mainWindow.loadFile(fileURLToPath(new URL("./dist/index.html", import.meta.url))); // doesn't fix it
// TODO: try vite base config https://vitejs.dev/config/shared-options.html#base
// or other options claude came up with
// maybe a separate build and copy all files into electron-dist/ or something?
// mainWindow.loadURL("/"); // for react router? nope
// mainWindow.loadURL("/play"); // for react router? nope
mainWindow.loadFile("index.html"); // showing error pageAside: it’s so crazy to spend days and days and days on this so that, MY END GOAL, like my ideal goal here, is to replicate exactly what I already have working on my website, into a 100MB executable. Just so that it can go into Steam, because people look at Steam.
Serving URLs
After giving up (hopefully temporarily) on running “directly” with some kind of
yarn run electron ., I tried using electron-build, copying everything, and
loading the app.
Lo and behold, I get the stylized app showing me a special new error I hadn’t seen.
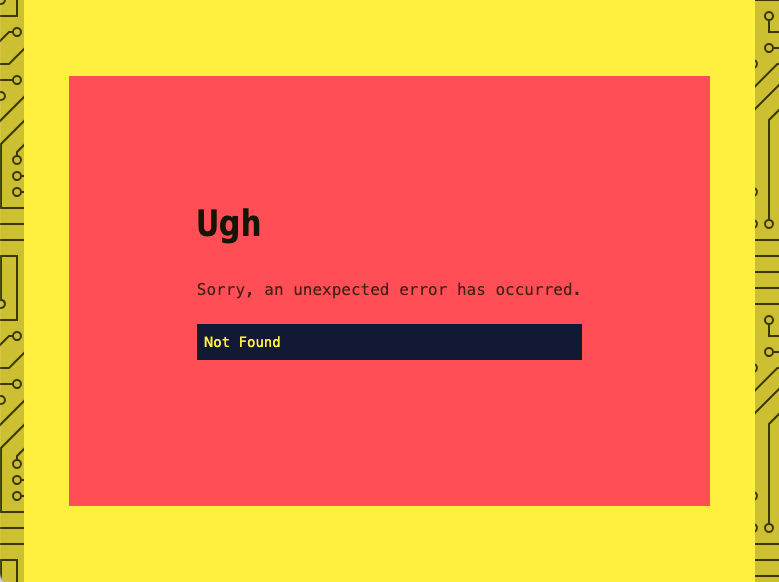
Opening the console to see the full error:
Error: No route matches URL "/Users/max/repos/ttmh/frontend/electron-dist/mac-arm64/ttmh-frontend.app/Contents/Resources/app/index.html"
So… something with the router. I think. That’s react-router(-dom).
The internet said I must switch from BrowserRouter to HashRouter, which I don’t want to do, because
- I want to change as little as possible
- Isn’t Electron supposed to jUsT wOrK
- I’m probably using it incorrectly in several places (I also know I definitely just straight up navigate to paths like
/thissometimes, which is probably wrong) - react-router’s docs say:
We strongly recommend you do not use HashRouter unless you absolutely have to.
I tried interrogating Claude01 on whether I really needed to do this. I mistrust both webdev StackOverflow and LLMs. It started telling me about Electron’s special implementation of the file:// protocol. And despite that Electron’s chrome(ium) conforming to the HTML(5?) history API (edit: or not?), because the app sends a request to the server for every page expecting to use http(s), the use of file:// screws things up (edit: even when not sending requests, I think it still wouldn’t work. But that was also happening).
Wait… does my app actually send a request to the server for every route change?
Because vite doesn’t log anything when you run the dev server, I never actually knew when something made a request to the frontend server. And because Cloudflare Pages always just worked, I never cared.
I fired up a python server in my dist/ directory
python -m http.server 4000Home page: beautiful, everything looks exactly perfect.
Then I click on a single URL and I get a total and utter 404 from, I assume, python’s server:
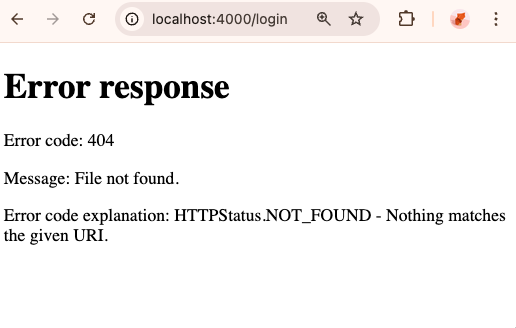
I can’t believe it. So the whole “local, client-side routing in react-router(-dom)” is actually doing server requests each time, reloading the same page, and then doing some kind of magic to display the correct one?
So wait, how does Cloudflare actually serve pages? Is it just sending index.html every time to every route? It can’t be. How would it know to do that?
Yes, it’s doing exactly that. Quoth the docs:
Single-page application (SPA) rendering
If your project does not include a top-level
404.htmlfile, Pages assumes that you are deploying a single-page application. This includes frameworks like React, Vue, and Angular. Pages’ default single-page application behavior matches all incoming paths to the root (/), allowing you to capture URLs like/aboutor/helpand respond to them from within your SPA.
Well I’ll be.
So now, do I
- embed a server in my Electron app? (this seems wrong)
- make a custom protocol like Claude is telling me I could try (
app://) and intercept stuff that way (scary?) - switch to the strongly unrecommended
HashRouter?
Well, one interesting note is that if I visit index.html on my local python server, I actually get
-
the same “Not Found” error page
-
with the console showing the same object (
Gp← minified?) -
with the same structure
{ "status": 404, "statusText": "Not Found", "internal": true, "data": "Error: No route matches URL '...'", "error": {} } -
with the same error message format
Error: No route matches URL "/index.html"
So hitting index.html should never work in the first place. This might not change my problem at all, but somehow it’s comforting to hit the same react-router(-dom) error in electron as with my python server.
I think what’s confusing me is the very basic first page in React Router’s docs says:
Client side routing allows your app to update the URL from a link click without making another request for another document from the server. Instead, your app can immediately render some new UI and make data requests with fetch to update the page with new information.
So I must be terribly screwing this up.
OK but regardless, I can only even consider doing it properly if I get something displaying on the page. (Though if I can get something displaying on the page… maybe who cares about doing it properly.)
OK yeah of course I can’t resist checking this
// current
<a href={nl.url} className="hover:underline">
{nl.display}
</a>
// how i'm supposed to be doing it
<Link to={nl.url}>{nl.display}</Link>wow, this is… what. So both links, if I hover over them, show this in the bottom of the web page.
![]()
Using my python server because it (appropriately) refuses to serve anything but /,
- clicking on the
<a>produces the not found page - clicking on the
<Link>loads the page. And instantly.
So I guess I’ve been missing out on all the react-router magic speed this entire time.
Now, I’m still tempted to have different pages because I think it’s good for SEO or something. But wow, holy cow.
I’m a bit nervous because I think some logic in my game breaks if I don’t get to hard refresh the page sometimes (e.g., nav away from game, nav back, state is weird). So I’m not sure I can entirely live without hard refreshes.
My question now is: how were the <a> links working at all? React router must somehow be intercepting the same old index.html reply my (ahem, Cloudflare’s) server is sending back the whole time, check the browser address bar, and then swap in the correct page without me even realizing I was doing it wrong.
OK, on second inspection, the local Link is not quite instant. Though, vs requesting from a server, it’s probably still faster, right? But the other thing I noticed is there’s some flashing happening. I recorded a video of switching between them and it’s just the empty page (w/ the circuit background) flashing between them; i.e., the absence of the content box. (Could I change this?)
I’m too curious—what is that <Link> actually doing? Can I inspect it?
<a class="hover:underline" href="/changelog">Changelog</a>You cannot be serious. It’s just an <a>???? There’s no JavaScript??? What is happening?!?!?!?!?!?
I think I need to go lie down. And then read the React Router docs again. Or not, and just keep googling how on earth it’s so hard for me to get my attempt at the most boring, typical setup to work.
Command-clicking a link to open in a new tab does hard-load the URL (as evinced by my python server still breaking in that case).
https://reactrouter.com/en/main/start/concepts#link tries to explain this, but I don’t know how they intercept the browser’s default behavior only in the exact cases they want.
Update from future Max: I think it probably attached a normal old
onClickhandler and did anevent.preventDefault, it’s just thatonClickisn’t rendered as an HTML attribute so I didn’t see it. So it’s probably not that crazy. Good reminder to come back to stuff the next day when it’s past 7pm.
All right, checking this out next: https://github.com/daltonmenezes/electron-router-dom
I think it just uses a Hash Router. All the extra code is to handle multiple windows.
export function Router(routes: RouterProps) {
...
return (
<HashRouter basename={windowID}>
<Routes>{transformedRoutes[windowID]}</Routes>
</HashRouter>
)
}The electron-vite project agrees with this too:
Electron does not handle (browser) history and works with the synchronized URL. So only hash router can work. … For
react-router-dom, you should useHashRouterinstead ofBrowserRouter.
I harassed Claude, Googled, and read Electron’s docs for a while longer to try to figure out exactly what aspect of Electron makes it not support the normal browser history, but I couldn’t understand it. So I’m going to just give up and try out the Hash Router. But first I need to try to have multiple configs with Vite.
Multiple Vite Configs
It is nice that playing with related tech in your free time can help your main project.
The other day I was trying to get a new repo set up using Vite instead of Webpack because using Webpack makes me want to set my desk on fire. But it was one of my “experiment” repos where I want to have a single build config but many sets of input→output. In other words, each experiment is fully separate—HTML, source TypeScript, the works—so that I don’t have to worry about refactoring as I learn new things and change everything. (I guess maybe they can share generated Tailwind CSS, that’s fine.) But I don’t want to set up a new build config or new repository each time.02
The solution to this was sitting right in front of me the whole time (“multi-page app”), but I spent enough time confused and reading about Vite and trying things that I feel a tiny bit more confident with, e.g., using multiple configs.
So I’m going to try splitting vite.config.ts into multiple options
vite.web.config.tsvite.electron.config.ts
… and then passing the config on the command line.
Spent some time trying to figure out how to send different environment variables for web/electron. I think if I don’t want to prefix them LIKE_THIS=here ... in the build commands then it’s better to just have whole separate file sets. A bit ugly copy-pasting dev/prod configs like this, but probably better than these critical variables living in strings in the package.json scripts.
Then spent some time trying to name things. Specifically the axis of web vs electron. Many other terms were taken. I came up with “deployment:”
| name | owner | examples |
|---|---|---|
| mode | vite | development, production |
| target | vite | modules, es2020, chrome87, firefox78 |
| deployment | me | web, electron |
| platform | electron-builder | win, mac, linux |
Refs:
- Vite: modes: https://vitejs.dev/guide/env-and-mode.html#modes
- Vite: build.target: https://vitejs.dev/config/build-options#build-target
- electron-builder: platform: https://www.electron.build/configuration/configuration#overridable-per-platform-options
Have started a deployment.tsx file that contains the implementation differences between deployments. Starting with just the HashRouter. We’ll see if this one file is enough, or whether something like code splitting will necessitate more over-engineering.
And… it works.
Wow, so switching to the HashRouter just super worked. Can’t login yet because that’s going to be a whole thing, but pages using <Link> can go to each other. All the vanilla webpages render.
Main glaring thing to fix is raw resource URLs, specifically images that start with /img/.... A bunch of these are sent from the server, too, for the game. Going to hold off on fixing the home page ones because the electron app might not have the home page at all. Playing the game is going to be the next main thing.
But just before that, I’d like to try out a super simple preload context bridge, inspired by the vite-electron-builder repo. Exporting the node process versions, and as a stretch goal, trying IPC.
Actually, scratch that, the vite-electron-builder has disabled the renderer sandbox. I’m still fuzzy on the preload vs renderer context, but a comment in their code says “Sandbox disabled because the demo of preload script depend on the Node.js api.” I have no reason to do this, so I’ll try some simple IPC instead.
Just kidding lol
Let’s try out IPC
https://www.electronjs.org/docs/latest/tutorial/ipc
What’s funny is the tutorial has one way of setting up IPC in the main process
function createWindow() {
// ...
ipcMain.on("set-title", (event, title) => {
const webContents = event.sender;
const win = BrowserWindow.fromWebContents(webContents);
win.setTitle(title);
});
}… but then when they go to explain it, they immediately do it differently:
function handleSetTitle(event, title) {
const webContents = event.sender;
const win = BrowserWindow.fromWebContents(webContents);
win.setTitle(title);
}
app.whenReady().then(() => {
ipcMain.on("set-title", handleSetTitle);
// ...
});So whatever, hoping that doesn’t matter.
I was having trouble where the IPC thing wasn’t being exposed in the renderer (window.electronAPI was just undefined). It occurred to me that I have no idea how to debug stuff in the main (or preload?) code. The prospects in the guide look grim:
https://www.electronjs.org/docs/latest/tutorial/debugging-main-process
I guess you have to expose a port for the “V8 inspector protocol” and then attach something to it that understands it?
Thankfully just specifying the directory of the preload script seemed to fix it:
{
// ...
preload: join(import.meta.dirname, "electron-preload.js");
}… because at least now I’m getting an error. But this error is what’s baffling me, and why I turned back to this devlog.
Unable to load preload script: /Users/max/repos/ttmh/frontend/bin/mac-arm64/ttmh-frontend.app/Contents/Resources/app/electron-preload.mjs
SyntaxError: Cannot use import statement outside a module
at runPreloadScript (VM4 sandbox_bundle:2:83494)
at VM4 sandbox_bundle:2:83813
at VM4 sandbox_bundle:2:83968
at ___electron_webpack_init__ (VM4 sandbox_bundle:2:83972)
at VM4 sandbox_bundle:2:84095The key here is Cannot use import statement outside a module.
But I don’t understand why it doesn’t think it’s a module.
-
I have
"type": "module"in my package.json -
I even tried renaming the preload script to
electron-preload.mjs -
My main script is a module, which seems to be fine
-
The
vite-electron-builderrepo builds its preload script into a module that uses modern ES imports -
The closest thing I’ve found so far online is this GH issue comment, which describes all the things you can’t ordinarily do in your preload file. But I’m only importing exactly what’s required:
import { contextBridge, ipcRenderer } from "electron"; -
Nevertheless, I did try turning on node integration, thinking maybe it needed that to allow modern (module)
importsyntax. That didn’t fix it.
Do I make this one file a require() style??
There’s a terrifying long (unresolved) thread in electron forge that doesn’t not make me think that may be required: https://github.com/electron/forge/issues/2931
OMG that was it. I guess preload can’t be an ES6 module in this context? The vite-electron-builder template does change lots of default settings, like sandbox: false, which may have been allowing import to work there.
Updates from working with Greg
- electron’s IPC requires both calling and handling with different function names for sync vs async
- able to shim in reading from
localStorageto get the JWT into the login page to send to server and try to get back session cookie - (re-remembering) chrome’s yellow colored failed cookie means that the server sent it back, but the browser refused to save it due to the cookie configuration
- this may be a mess w/ the client being local and on
file://, whereas the server’s cookie is expecting a bunch of stuff to be first party, specific domain, and secure - to refactor:
- could refactor all privileged
fetchcalls to pass as bearer auth, - … or change this only on the electron side, and have server accept both
- i’m not sure the choice really matters. sure with a hidden cookie JS can’t get it, but the user can always find it anyway, so i’m really only defending from malicious code
- could refactor all privileged
- this may be a mess w/ the client being local and on
Electron cookies: the good
cookies, in general, are cool, because the following works:
-
(Chrome) If you manually set the (first party, session) cookie, are you suddenly logged in?
- yes
-
(Electron) If I save a cookie, can I see it in dev tools?
- yes
-
(Electron) Will the (electron) browser then use it for requests?
- yes
If I set the following cookie (in Electron’s main process) and hit the production website, it all works and the game can be played (first time ever!):
const cookie: CookiesSetDetails = {
url: "https://talktomehuman.com",
name: "session_jwt",
value: "(REDACTED DUH)",
domain: "talktomehuman.com",
path: "/",
secure: true,
httpOnly: true,
// expirationDate: // TODO: maybe set (unix seconds), maybe OK (expires w/ session)
sameSite: "lax",
};
await session.defaultSession.cookies.set(cookie);However…
Electron cookies: the bad
Summary:
- I don’t think the domain (let alone protocol) can mismatch
- I don’t think cookies work on
file://at all
… the above has stringent requirements:
- the
domainseems to have to match the URL exactly (or vice versa). Because usingapi.talktomehuman.comas the domain results in the following error:
Error: Failed to set cookie - The cookie was set with an invalid Domain attribute.- the above error is also triggered by trying to set the
urlfield to anything remotely useful for a local context, likefile://
Some additional info found in a few places:
https://github.com/electron/electron/issues/4422#issuecomment-182618974
Seems to indicate URL/domain cookie matching guidelines (? rules?) which… we’d totally violate w/ file:// and on a different domain.
https://github.com/electron/electron/issues/27981
- cookies aren’t supported on custom protocols
- Chromium does have a flag that would add
file:to the “cookieable scheme list,” though it’s unclear to me whether that flag is modifiable from Electron- looks like probably not: “we don’t set things up such that file is allowed”
- another comment from that issue where someone needed cookies to use a third-party SDK: “The only other option I see is to run a local server, even in production, and server up the file via http, which would be less than ideal.”
- another comment had a couple interesting bits:
- tweaking CORS (I think on the backend) to prevent it from blocking requests using
file:// - intercepting the HTTP protocol—rather than registering a new file protocol—in in order to get cookies to work. (this is kind of mind bending and i don’t fully understand how this works)
- tweaking CORS (I think on the backend) to prevent it from blocking requests using
https://github.com/electron/electron/issues/22345#issuecomment-1057130188
Some code (and refined by the next two comments) that intercepts web requests, checks the headers, and modifies cookie parameters on the fly. Probably not necessary since I control the backend, too, but good to know such hackery is (or at least was, in 2020) possible.
https://stackoverflow.com/questions/50062959/electron-set-cookie
Electron: setting a cookie with file://
-
The first answer, by the author in 2018, registers a new scheme (
app://) to overcome thefile://limitation. But a comment from 2019 says this no longer works.The fact that it doesn’t work checks out with what I learned above (GH issue from 2021 that cookies aren’ supported on custom protocols).(see third answer) -
The second answer is useless
-
The third answer was from the 2019 commenter, but they probably just changed some configs and ended using a custom protocol (
app://) that presumably had cookies working for them. (I’m not sure exactly when it stopped working.) -
The fourth answer (2023) is probably the most helpful. They outline two scenarios:
-
Hitting a remote URL (i.e., using the standard
http(s)://scheme), you can set Cookies using Electron’s API—at least, for that particular domain- This is true; I verified it in the section above
-
Hitting a local URL (i.e., using
file://) and then trying to make afetchcall to a server, they had trouble trying to “set or retrieve cookies.”- However, from what I understand of Chrome / web browsers, it makes sense that you wouldn’t be able to simply set cookies from HTTP headers in the normal flow, because (a) we’re on
file://, (b) the origin is different - So for me, the interesting question is whether we could set them in a privileged way (e.g., in the main process) and then have the browser simply use them—send them with requests. (Guessing no.)
- Their solution was to reduce security settings (enable node integration; disable context isolation), then use Node’s HTTP module to manually make
fetchcalls, constructing the HTTP headers w/ cookies by hand.- At this point, I’d might as well just use bearer auth.
- However, from what I understand of Chrome / web browsers, it makes sense that you wouldn’t be able to simply set cookies from HTTP headers in the normal flow, because (a) we’re on
-
https://developer.mozilla.org/en-US/docs/Web/WebDriver/Errors/InvalidCookieDomain
This is Mozilla’s documentation on WebDriver, so it’s not necessarily the same in Chromium or Electron. However, some concepts seems relevant:
-
it mentions documents being “cookie-averse” if they’re not served over
http://,https://, orftp://- they specifically mention
file://being cookie-averse - Chromium’s list, IIRC, was:
http://,https://,ws://,wss://
- they specifically mention
-
it also mentions problems with mismatched domains. For example:
example.com— current domainexample.org— trying to add a cookie for this domain fails
high level Q to electron discord
Ahh, discord and/or github discussions, where your problems go to die silently.
hey all, i have a very high-level question. do major electron apps like slack, discord, etc.:
- package their HTML files locally, and run over
file://?- package their HTML files locally, and run a local webserver
(http://localhost:...)?- package their HTML files locally, and use a custom protocol (e.g.,
app://)?- just open a browser window to their remote websites and run over
https://?- Something else?
For context, I’ve been working on method 1: trying to get a relatively simple app to run over
file://. But I seem to constantly run into issues and rough edges, like routing and cookies. I’m wondering whether anyone knows how the major apps run?
next steps
two main paths forward from where I stand:
-
send auth headers directly w/ bearer auth in
fetch()calls- would the lack of cookies have issues w/ redirects and/or the loader logic in the router? i.e., with the –>
/loginredirects? - maybe not, because we’re always able to GET index.html, the only webpage on the frontend. I think all interesting calls must be manually
fetch()d w/ cookie auth to backend - issues in
public/still remain? how hard to address?
- would the lack of cookies have issues w/ redirects and/or the loader logic in the router? i.e., with the –>
-
abandon a local build entirely and use a local web server or browser window to the remote site
- potentially include a local landing page for the auth flow?
I’m still tempted to try 1, probably because I’m a fool. It might be worth sketching out what 2. would look like in more detail.
Investigating Slack
Slack is a legit Electron app. (One of the first?) Do they package all assets locally and run on file://, or another protocol? Or are they just serving their website from an Electron shell?
SLACK_DEVELOPER_MENU=true open -a /Applications/Slack.appsome assets exist in bundle locally, but appears to load page and tons of assets from URL (the only document is from https://app.slack.com/client/XXXXXXXXX/YYYYYYYYYY)
however, if you open without internet, it still works! even reloading is fine. however, force reloading displays a blank screen. but then getting back online doesn’t fix it without a full reboot.
Note from investigating Service Workers later:
“If you force-reload the page (shift-reload) it bypasses the service worker entirely. It’ll be uncontrolled. This feature is in the spec, so it works in other service-worker-supporting browsers.”
checking “Disable cache” and reloading keeps the layout. However the network tab indicates the document involves (was served by?) a “Service Worker” (web thing I’ve heard of but don’t know anything about). And if you look into the details, it says
Source of response: ServiceWorker cache storage… so it might be that the doc is retrieved dynamically by a service worker which has its own caching logic that circumvents the “Disable cache” check.
Other notes:
- a huge amount of Fetch/XHR are from “gantry” — all “pixel” and things named
track/. kind of depressing. - 1 Doc, 3 CSS files, ~12 JS, 2 fonts (lato in 4 styles + slack icons), ~ 20 images, ~ 12 mp3s, 0 manifes / WS / Wasm, and ~50 JSON files (“Other”)
- JS all prefixed by “gantry” or have it in the query string—maybe for ultimate tracking your tracker proxies all your assets?
- Turns out Gantry is their base library for all frontend things. So it’s handling many aspects of the code: bundling / splitting (probably managing webpack), caching (via Service Workers), fetching (also Service Workers relevant), and common internal tooling (tracking, profiling).
Looks like they may have written about this: https://slack.engineering/service-workers-at-slack-our-quest-for-faster-boot-times-and-offline-support/
“When you first boot the new version of Slack we fetch a full set of assets (HTML, JavaScript, CSS, fonts, and sounds) and place them in the Service Worker’s cache. We also take a copy of your in-memory Redux store and push it to IndexedDB. When you next boot we detect the existence of these caches; if they’re present we’ll use them to boot the app. If you’re online we’ll fetch fresh data post-boot. If not, you’re still left with a usable client.”
So it’s literally a chrome shell w/ a service worker script (if that! honestly it is probably loaded too).
Also interesting:
Note that most binary assets (images, PDFs, videos, etc.) are handled by the browser’s cache (and controlled by normal cache headers). They don’t need explicit handling by the Service Worker to load offline.
I still wonder why so many assets were bundled.
Service Workers are reinstalled every time their script changes. They update their service worker every time any asset changes as well:
“Every time we update a relevant JavaScript, CSS, or HTML file it runs through a custom webpack plugin that produces a manifest of those files with unique hashes (here’s a truncated example). This gets embedded into the Service Worker, triggering an update on the next boot even though the implementation itself hasn’t changed.”
It’s kind of interesting. It feels wrong. Like ultra heavy-handed cache invalidation.
More notes:
- They key everything by (build) timestamp and only request from one timestamp to ensure compatibility. (Can’t tell whether this is trivial or interesting.)
- Their service worker then proxies literally all
fetchrequests, serving from the Cache if it exists or passing through.
On caching API responses:
"A common workflow at Slack is to release new features alongside corresponding changes in our APIs. Before Service Workers were introduced, we had a guarantee the two would be in sync, but with our one-version-behind cache assets our client was now more likely to be out of sync with the backend. To combat this, we cache not only assets but some API responses too.
The power of Service Workers handling every network request made the solution simple. With each Service Worker update we also make API requests and cache the responses in the same bucket as the assets. This ties our features and experiments to the right assets — potentially out-of-date but sure to be in sync."
(emphasis theirs)
I don’t fully understand. Need example.
One more interesting thing: what’s embedded at the top of the page (<script> and <style> in <head>). These are presumably meta observability stuff (profiling and tracking), bootstrapping, offline detection, and barebones skeleton setup.
-
script: primarily
haveAssetsLoaded()andreloadIfIssue()- utilities for
- timing loads and logging
- sending a beacon to servers if trouble loading
- showing trouble loading overlay over whole window (document)
- the “trouble loading” detector is nice:
- show the trouble loading overlay
- set “online” listener that simply reloads the page
haveAssetsLoaded(): checking whether assets (CSS / JS) all loadedreloadIfIssue(): checks assets, hooks up online listener, reload retry logic, CDN fallbacks, and clearing cache / service worker
- utilities for
-
style for trouble loading overlay
-
script: hooking up profiling for long tasks
-
script: dark mode w/ hardcoded CSS (probably to prevent a bright flash)
-
script: setup a global error handler that records all errors and sends them to slack
-
script: grab the CDN location
-
script: preload fonts by creating links to them and setting preload + prefetch
-
script: mysteriously set
jLen = 4andcLen = 3(IIRC these are lists of JS and CSS assets) -
(+10, 11) script: w/ profile, force load + inject 3 (
cLen?) stylesheets (“slack kit”, “boot”, “helper” styles) into head
Scripts in body:
- translate the trouble loading error message
- download localization JSON files
- webpack shims and sets up enormous asset lists (json, css, img, animations, and probably all the JS too)
- (+ onwards) load manually specified JS files, I think these are the ones referred to by
jLen
I’m not positive exactly where all the loading is kicked off, but I didn’t search for it, and there’s a lot of minified code.
I’m not even sure whether they have an initial index.html inside. app.asar is 12 KB. It contains:
- a tiny index.js (which is the main script)
- this just points you to the
asarfile for your architecture (app-x64.asarorapp-arm64.asar) - I was thinking there ought to be more but this is probably the Mac-specific build
- this just points you to the
- the package.json, which is cool because it contains
- all their dependencies and dev dependencies
- all their build scripts
OK cool, let’s check out my app-arm64.asar. It has
dist/w/ code bundles, mp3 files, fonts, localization, iconsnode_modules(w/ some 1-liner gems, likenumber-is-nanandisarray)- a nearly-identical
package.json, but noindex.js. The main is:./dist/boot.bundle.js
The code bundles in dist/:
497.bundle.jsbasic-auth-view.bundle.jsboot.bundle.jschild-preload-entry-point.bundle.jscomponent-preload-entry-point.bundle.jsmagic-login-preload-entry-point.bundle.jsmain.bundle.jsnet-log-window.bundle.jspreload.bundle.jsrenderer.vendor.bundle.jssettings-editor.bundle.js
And there are 3 HTML files:
basic-auth-view.htmlnet-log-window.htmlsettings-editor.html
Tracing code path:
boot.bundle.js(obfuscated)- seems like utils
- one interesting thing, I do see
slack://; so that’s one potential protocol - references
./main.bundle.js
main.bundle.js(obfuscated)- does reference
app://resources/${o}.html, which is interesting because- another protocol?
- what goes in there appears to be top-level windows that are created: the “about slack” box, a “basic auth view”, the main window (I think), a log viewing window, and a settings editor
- there’s no HTML files in
resources/. probably downloaded. or elsewhere? - since it’s
app://resources/, the code is handling where to find it, so it could be saved anywhere
- I also see
app://resources/notifications.html - I see what looks like the electron window creation section, which seems to specify:
- preload: the
component-preload-entry-point.bundle.jsscript - URL: I think it’s the
app://resources/${o}.html.toString()ois inspected and used to set thewindowOptionsargument
- preload: the
- does reference
Not other concrete pointers to HTML files, so I think it’s time to check out the ones we have.
Based on the names, basic-auth-view is the best candidate for an opening view. It has an empty HTML <body> tag. Of note:
- a very lengthy
<meta>w/ aContent-Security-Policyincluding a bunch of slack domains - loads
renderer.vendor.bundle.js(why “vendor”?) - loads
basic-auth-view.bundle.js
renderer.vendor.bundle.js
- very short
- seems to setup handful of react functions
- bunch more utils that look very react-y (
componentWillMount) - ok this might be either React or a barebones subset. “vendor” would make sense
basic-auth-view.bundle.js
- sets up Sentry
- sets up font styles
- sets up CSS
- buncha little utils (I think from Sentry)
- react v16
- redux
onecouplefewbuncha things copyrighted by microsoft- yo why isn’t all this “vendor” lol
- nice big sentry error reporting message about running in the wrong Electron process & possible causes and solutions (not sure whether Slack or Sentry wrote this)
- only at the bottom, some code about setting a username / password for a proxy or server
Might end my exploration now, because there’s more stuff (e.g., searching “magic link”) reveals a bunch more in component-preload-entry-point.bundle.js (and the main bundle, and the magic link bundle).
One other fruitful exploration might be the ipcRenderer (occurs in a bunch of places)
Overall, this was very educational. My takeaway re: loading is:
- slack definitely loads a huge amount of stuff from their servers
- the service workers update the app in the background as you run it (i.e., you never update the electron app itself) by downloading and caching new versions of all the assets
Interestingly, I still don’t have a super solid understanding of how we get
- from what’s downloaded in electron (all the JS bundles above)
- to the working single main HTML page
The working single main HTML page is gotten from a Service Worker on load. On force reload (“force cold boot” in their terms), it is retrieved from https://app.slack.com/client/XXX/YYY. The enormous mess of JS is server (edge) loaded, then Service Worker-loaded, too.
Is the electron stuff (main and preload) able to be updated with the Service Worker? Probably not, I would guess. I wonder if it can self-update, or if it actually downloads new app versions.
Remaining questions:
-
is all the downloaded JS bundles from the ASAR actually used during normal app running? or is it deprecated as soon as we have a cache downloaded from the server?
- my thinking right now—barring understanding any electron updates—is:
- the renderer’s assets (HTML, CSS, JS) are Service Worker-managed, heavily cached, etc. And never sent to client
- but the main / preload (electron-specific) assets are not
- my thinking right now—barring understanding any electron updates—is:
-
does the initial load hit
file://? (and are we usingapp://,slack://,https://for other stuff?)- the page assets all seem to come from
https://directly
- the page assets all seem to come from
Investigating file:// usage in the ASAR-bundled code:
-
component-preload-entry-point.bundle.js,main.bundle.js, andpreload.bundle.jsall have this gem:.replace(new RegExp(`(file://)?/*${r}/*`,"ig"),"app:///")This may be in Sentry’s code, though.
-
the other instances I see are error reporting and polyfills
-
hard to see it directly loading anything
On the other hand, we do see (main.bundle.js)
protocol.registerSchemesAsPrivileged()for- “sentry-ipc”
- I’m pretty sure “app”
protocol.handle("app", ...)
Some interesting bits found around the protocol handling (in main.bundle.js):
- if the protocol isn’t “app”, error: invalid protocol
- (if url.includes(“..”)) “Traversing paths upwards not allowed in app:// protocol.”
- (if host !== “resources”) “Host must be resources for app:// protocol.”
- (if (!w.pathname || w.pathname === “/”)): “Missing path in app:// protocol.”
- if pathExists(…), fetch, or error: “Requested file not found.”
- finally, “unexpected error in app:// protocol handler.” (“app://” hardcoded in string)
It’s still unclear to me whether file:// is used at all, but it certainly seems app:// is used. I don’t recall so far whether a custom protocol has any benefit over file://, though it might. Minimally, wrapping allows intercepting all requests yourself, so I could see that alone as a justification.
If I had to guess, I would say that file:// is not used.
- The only code section that checks for it might be from a third party; it has a github link and code that checks for FF / Safari nearby.
- The rest of the code seems to try to regex and/or substring it out.
So I’d guess they register app:// early on, load the initial auth views using it, and then redirect to the full https:// view. I’m not positive that I need to do this rather than use file://, but it’s helpful to see.
Service Workers
(NB: chronologically done in mid section of Slack investigation above)
Checking out https://developer.chrome.com/docs/workbox/service-worker-overview
“Service workers are specialized JavaScript assets that act as proxies between web browsers and web servers. They aim to improve reliability by providing offline access, as well as boost page performance.”
The term “asset” freaks me out.
Visiting chrome://serviceworker-internals/, I have 545 of them. 3 are running on that internal page, all chrome extensions. The rest are stopped.03
“An indispensable aspect of service worker technology is the Cache interface, which is a caching mechanism wholly separate from the HTTP cache.”
and, from MDN:
“The Cache interface provides a persistent storage mechanism for Request / Response object pairs that are cached in long lived memory.”
So this is all checking out.
Service workers can intercept network requests. Since the Cache is for (Request, Response) pairs, this makes sense. It’s pretty interesting though.
Some more notes:
- scoping is based on subdirs; as such, usually install in root of domain
- progressive enhancement is the idea; page should work without it, but (future visits) can be sped up with it
- browser automatically does byte-by-byte comparison and updates to new version if script changes (I think). don’t change the script name on update.
- service workers have detailed lifecycle w/ installing, activating, waiting, running. it seems to take multiple page views for it to run (can accelerate on refreshes w/ dev tools)
- run on own thread, like web workers
- two kinds of caching: pre-caching (grab what you might want) and runtime caching (intercept network requests)
Methods
| sync | async | |
|---|---|---|
| preload | send() |
invoke() |
| main | on() |
handle() |
Footnotes
All the gpt-4s have gotten stupider these days, to my dismay. ↩︎
After writing this out, I realize a new vite config for each experiment probably would have been fine… though I guess running them all would have been annoying, maybe? ↩︎
Aside, it’s always a bit annoying that chrome extensions are identified as gibberish
chrome-extension://schlabadadobabambado. Each one has their URL listed 4 times and zero mention of its name. ↩︎
