Automating Screenshots
Relishing Making One's Own Tools
I wrote a small script to automate taking screenshots of webpages.
The script summoned enough little edge cases that I thought it’d be a fun topic for a devlog. Here’s a few examples of what it captures:

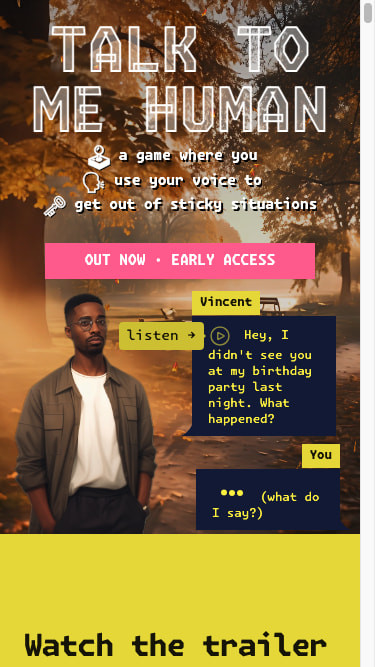
Top: Left: Desktop and Bottom: Right: mobile-sized screenshots of the landing page. Give it URLs and screen sizes and off it goes with the cross product.

Scrolling down the Press Kit page and taking screenshots as we go. This is only slightly complicated because (a) Selenium has no direct scrolling API, (b) my pages have a stupid structure that makes them more annoying to scroll.

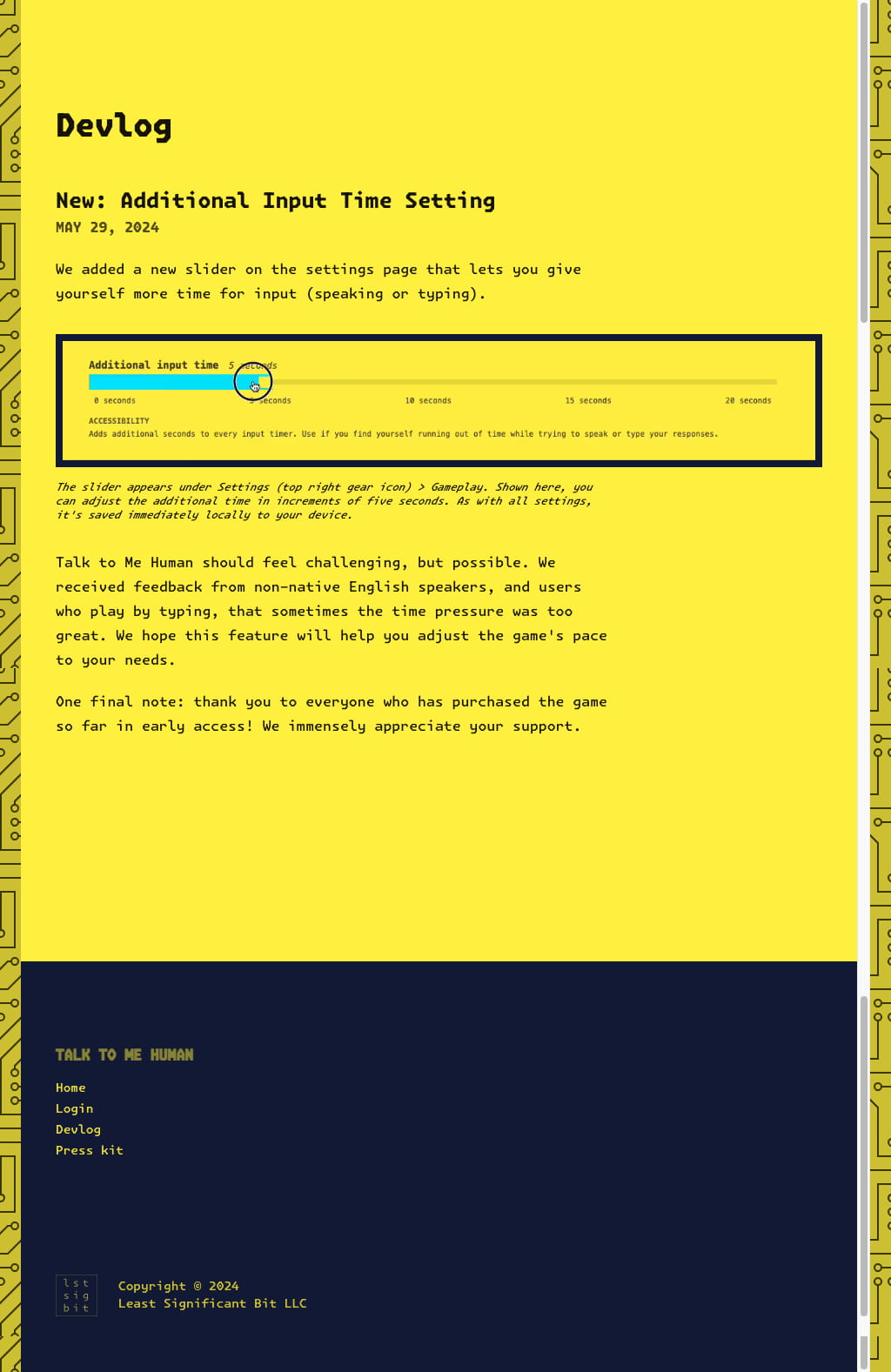
(click picture for full resolution) My crowning achievement, the One Big Image screenshot of a whole webpage (Press Kit, desktop resolution).
You can jump to the final code listing or read on.
Pictures: An Easy Visual History
This all started when I made a bunch of design changes to the Talk to Me Human website.
I thought it’d be nice to track changes to the site by capturing screenshots of the pages. Of course, I could always access the old versions by checking out an old commit in the repository. But I’m never going to do that. I will open image files I have lying around though.
Top: Left: old Bottom: Right: new. Key changes: adding a top bar (else it just feels imbalanced), toning down the main colors, switching to a more legible font, and doing centering and width-limiting on the body content. It makes a page much more pleasant to read.
I knew that Chrome can run in headless mode and is scriptable. Why not just have a quick script to load the page and take some screenshots?
As usual with programming, this simple idea became a rabbit hole. And as usual with programming tools, they’re the most fun rabbit holes to jump down.01
Basic Screenshotting is Delightfully Simple
Download Selenium from an it-looks-too-old-to-be-true website (it’s not), get some Python bindings, and you’re off to the races:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# Setup
chrome_options = Options()
chrome_options.add_argument("--window-size=800,600")
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
# Look how easy this is
driver.get("https://talktomehuman.com")
driver.save_screenshot("ttmh.png")
# Bye
driver.quit()By the way, I’m roughly reconstructing these intermediate versions from memory, so take them with a grain of salt. (Full script is at the end.)
Et voilà:

Baby’s first screenshot.
You Need JS to Scroll
I was going to poke fun at the Selenium Python docs for tucking the arcane feature of scrolling the webpage into the FAQ rather than the docs proper. But since it involves running JavaScript rather than some method on the Python API, I shall abstain.
driver.execute_script("window.scrollTo(0, 100);")Wait, scratch that. Everything in Webdriver (navigating, finding elements, waiting for conditions) looks like stuff you can do in JavaScript.
But it doesn’t work! Nothing changes because I don’t actually want to scroll window in my case.
Oops My Page Scrolls an Inner Element
Part of the design of Talk to Me Human is putting the game in box. On most large-ish screen resolutions, a series of width-limiting stops and a vertical margin make the game’s play area sit in a visible region.
This boxy design was intended to make the application feel more like a game and less like a webpage. Webpages allow you to scroll the whole visual content vertically, or in rare artsy or annoying cases, horizontally. On the other hand, games typically exist in a fixed screen size, and manage the display and navigation of their content internally.

Here you can clearly see the “game in a box” design, with margins on all four sides. All gameplay and navigation takes place within that box.
All of Talk to Me Human’s initial pages were for core gameplay: the start screen, all the main gameplay views, and the progress and settings screens. For those pages, the game-y all-margin layout makes sense, at least to me.
But now, the site has expanded to also include pages that function like a traditional website: landing page, changelog, press kit.
The implementation of the all-margin layout is at the very root of the website: at the <body> element. This means it’s outside of React’s purview, so it’s not trivial to change without altering the site’s build at a deeper level.
All this is to say: website-y pages all scroll within an inner element, rather than the window itself. So simply running window.ScrollTo() doesn’t work, because the window can’t scroll. The window is the size of the viewport.
Instead, we must find the large, scrolling element inside the document and scroll that:
driver.execute_script("document.querySelector('#foo').scrollBy(0, 100)")This finds the element with ID “foo” and scrolls it down by 100 pixels.
Finally, we’re getting somewhere!

Landing page first and second screenfulls via actually scrolling.
Document Loads, then Elements Appear
If you lived through the jQuery days, you remember seeing:
// wait for page to load before running your JS-spaghetti
$(document).ready(() => {});
// or, mind-blowing shorthand
$(() => {});It still amazes me that JavaScript is both (a) probably most folks’ first experience with programming, and (b) plumb full of wildly terse, magical, functional stuff. Talk about throwing them in the deep end.
If, like me, you lived through the jQuery days but never actually used jQuery, then you remember Googling the web-native alternative countless times:
document.addEventListener("DOMContentLoaded", () => {});I will admit I just Googled this, again.
Selenium has its own way of going about this, where you import a mess of Java-like classes By and WebDriverWait and EC (expected_conditions) and construct a frankenstein code sentence:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)If thou hast not penned Java, how canst thou know its scent?
I started doing this, but quickly realized that my pages have inconsistent elements without predictable IDs. Plus (spoiler) we’ll need to wait for stuff to trigger on scroll anyway. So we just do a good old fashioned.
time.sleep(1)Programming’s forbidden fruit. Burn baby burn.
Scroll, Snap, Repeat
We’re loading, we’re waiting, and we know how to scroll. Let’s start taking some pictures. Conceptually this is very simple: just scroll and snap.
# Please pretend we know `n` and `screen_height`.
for i in range(n):
driver.execute_script(f"document.querySelector('#foo').scrollBy(0, {screen_height})")
driver.save_screenshot(f"ttmh-{i}.png")But here’s a hiccup. Remember those y (vertical) (height) margins we were talking about before? If we scroll by the screen height, we’ll be scrolling by too much, because the actual visible portion of the element we’re looking at is smaller.
As I was writing this, I realized nothing in my script accounted for this. I looked again and realized I accidentally worked around the problem entirely by picking a screen height that’s too small to have vertical margins.02
Great! Let’s move on to more pressing matters. Why is everything empty.
Oops: Stuff Loads on Scroll
I admit, it’s a trend. And I despise it when done badly. You see it in overwrought marketing sites that try to feel too fancy. For all kinds of things: hotels, restaurants, JavaScript libraries.03
Appearing on scroll.04
And I have committed this sin. Maybe in a few years we can just turn them all off.
But for now, it’s here, and boy is it making all my automated screenshots just completely empty.
Look ma, no content!
The weird part was: the phone screenshots are all fine!?
To understand why, we must dig in. I haven’t described it yet, but here’s how I capture screenshots for different window sizes:
- load each the page once
- loop over window sizes
- scroll and take a bunch of screenshots
- loop over window sizes
sizes = {
"desktop": (1024, 768),
"phone": (375, 667),
}
# load each page once (just one url here for simplicity)
driver.get(url)
# loop over window sizes
for size_name, (w, h) in sizes.items():
driver.set_window_size(w, h)
# scroll and take a bunch of screenshots
for i in range(n):
driver.save_screenshot(f"ttmh-{size_name}-{i}.png")
driver.execute_script(f"document.querySelector('#foo').scrollBy(0, {h})")I must stress this is still basically pseudocode I’m piecing together to illustrate where we’re currently at with the story. But honestly, code snippets like this might be more helpful than my full ugly script at the end, because your edge cases might be different than mine. Or just more fun to write your own ugly big script, etc.
So we do this, and the desktop screenshots are all empty, but the phone ones are filled with the glorious appear-on-scroll elements:
The phone-sized screenshots of the same three locations as above are filled with all the content that appears on scroll.
Why? You may have guessed the answer: the phone-sized loop runs second.
Since it’s all one page on one browser, the desktop viewing scrolls down to each part of the page, revealing everything that gets revealed on scroll. Then, by the time the phone-sized loop runs, it’s all visible.
Great, I think, we’ll just scroll to the bottom first, then scroll back up, then begin the whole thing.
# Get the height, scroll to the bottom, then scroll back to the top.
scroll_to = driver.execute_script(f"return document.querySelector('#foo').scrollHeight")
document.querySelector('#foo').scrollTo(0, {scroll_to})
time.sleep(5) # make reeaaally sure (this doesn't help)
document.querySelector('#foo').scrollTo(0, 0)Silly me, thinking it could be so easy.
“Not so fast,” says Framer Motion, manager of my irritating web design. “That doesn’t count, foolish boy. You can’t just blast to the bottom of the page, you must SEE each element I wish to present to you in its proper location.”
We must instead scroll down the page, piecemeal, pausing as we go. Only then is everything visible.
# before we take any screenshots at all, we do this to scroll down painfully slowly
for target in range(0, scroll_to, scroll_by):
driver.execute_script(f"document.querySelector('#foo').scrollTo(0, {target})")
time.sleep(0.5) # I'm sorryThis is what we call pRoDuCtIoN cOdE.
It works!
Desktop-sized screenshots down along the page, now filled with their appropriate animated info boxes.
Here’s the silver lining of all of this: remember above when we could have properly figured out how to wait until particular elements on the page were visible using Selenium’s WebDriverWait util EC By syntax? But instead we just threw in time.sleep() and moved on?
Well, thank Eich05 we didn’t do that properly, because we would have thrown it out anyway in favor of this scrolling sleep.
This is a good lesson I am continuously learning to keep in mind: don’t worry too much about doing it right until the whole thing works. Because you might not have to do it at all.
Nobody 404s Me Anymore
Now that basic screenshotting was working, I had the bright idea of over-engineering my webpage loop to check if a page 404s before trying to take pictures of it.
Interestingly, checking HTTP response codes is explicitly-out-of-scope for Selenium:
We will not be adding [reading HTTP status codes] to the WebDriver API as it falls outside of our current scope (emulating user actions).
…
If we attempt to make WebDriver the silver bullet of web testing, then it will suffer in overall quality.
— GitHub
Ah, reminds me of dealing with the Golang authors,06 and how they wouldn’t implement min or max.07
No problem, I said, and imported the faithful requests library. I then proceeded to get 200s from all possible URLs on my website.
Wait… what?
# Looks good
❯ curl -s -o /dev/null -w "%{http_code}" https://talktomehuman.com/
200
# wait what
❯ curl -s -o /dev/null -w "%{http_code}" https://talktomehuman.com/asdf
200
# no
❯ curl -s -o /dev/null -w "%{http_code}" https://talktomehuman.com/nowaywaitreallythiscantexist
200
❯ curl -s -o /dev/null -w "%{http_code}" https://talktomehuman.com/even/this/in/here/seriously
200Being fundamentally confused about how your own technology runs is like coffee for the technical mind.
I love these humbling moments where you realize you have absolutely no idea how something very basic about your product is working.
At first I thought this was React Router. Then I tried serving my site with the good old python -m http.server and saw 404s. Turns out both Cloudflare and Vite’s dev server are so helpful that I didn’t even know what they were doing. Here’s Cloudflare:
If your project does not include a top-level
404.htmlfile, Pages assumes that you are deploying a single-page application. This includes frameworks like React, Vue, and Angular. Pages’ default single-page application behavior matches all incoming paths to the root (/), allowing you to capture URLs like/aboutor/helpand respond to them from within your SPA.
So: you always get 200s.
It was at this point that I realized I was doing something pointless, and just resigned myself to keeping a list of URLs and being fine with the occasional failure. This was the right call.
One Image. To Rule Them All.
Back in the Game Boy era, I was fascinated by maps of entire areas that you’d see in strategy guides, but could never witness in-game. For example, a whole area in Pokémon Blue, of which your screen would ever display a slice.
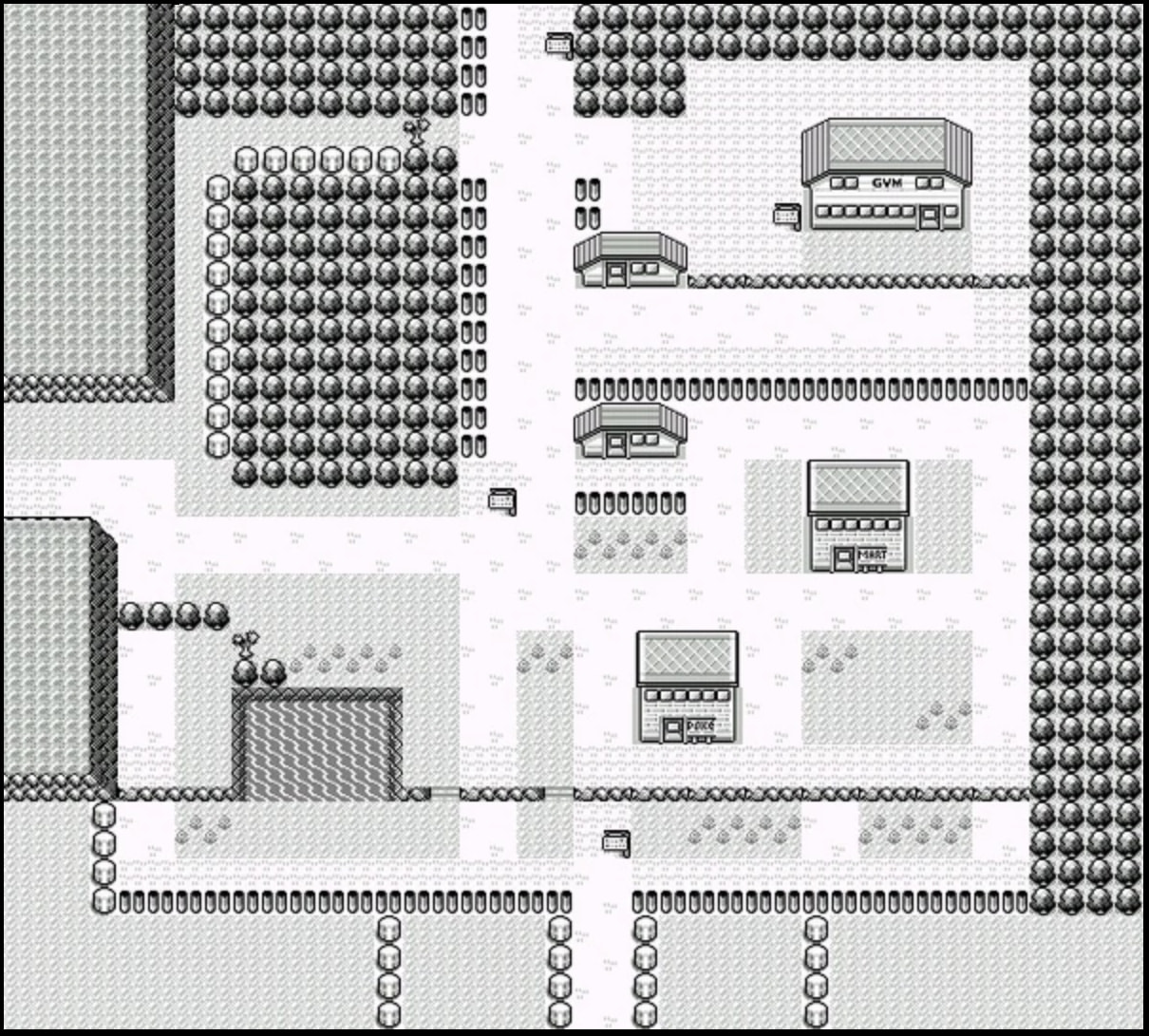
Decades later self psychoanalysis: these images lit up three joy centers of my brain: (1) how did they do that? (2) wow, games! (3) wow, maps! Source: Fandom (CC-BY-SA).
I never really understood how they did this. I assumed they were either:
- Big raw images of the underlying game’s map
- Spliced together somehow from individual screens
In the same spirit, I wanted to get one big image of each webpage. I started with strategy 1: try to get a big image all in one go.
Since I can control the height of the virtual browser window, why not just set it to something ridiculous?
Unfortunately this does not work because of the structure of my HTML page. As mentioned above, there’s an inner element that gets height limited.

The landing page zoomed waaaaay out. Just a lil box. Not the whole page.
And, as mentioned before, because this layout is at the very top of the website, outside of React, changing it would mean making changes to my build process. I didn’t want to make any major changes just to get these screen shots.08
Take Two: Stitching Together
Since strategy 1 (one big image) seemed like too much work, I instead tried splicing together a bunch of small screenshots.
This worked well—minus the scrollbar looking a bit weird. Except… what’s going on here?

One does not simply tile their screenshots.
Ah, of course, you can’t just scroll and tile, because the browser won’t scroll past the end of the element. So your last screenshot ends up with overlap. Fortunately, we can compute this and subtract it.
One does simply tile their screenshots.
Final code listing
In case it helps anyone else get this running on their own, here’s the complete Python script to screenshot webpages, with all the oddities and quirks.
If you want to run it, you’ll need to first install:
selenium(these are Python bindings; also need underlying tech)Pillow(for stitching)tqdm(just a progress bar)
"""
Requirements:
- scrolling element CSS selector. (typically just use body)
(NOTE: could customize per-page)
- list of pages
- out dir
- two modes: scroll and whole img
1. scroll: different window sizes:
- desktop
- phone
2. whole img
- simply stitch together (1.) rather than try to grab whole thing
Note on 404s:
Interestingly, you can't get response headers from Selenium, so you can't get
a 404 until stuff starts failing. Their rationale is decent:
> We will not be adding this feature to the WebDriver API as it falls outside
> of our current scope (emulating user actions).
>
> If we attempt to make WebDriver the silver bullet of web testing, then it
> will suffer in overall quality.
>
> - https://github.com/seleniumhq/selenium-google-code-issue-archive/issues/141
Instead, we could use HTTP-level functionality from something like requests.
HOWEVER, since my site is an SPA that uses react-router, it is fine with all
routes (it just returns the same index.html file), and so will always return
HTTP 200. The actual *content* would indicate a "soft 404" (i.e., no matching route
within React Router). So we could actually use webdriver to get this. However, this is
such a niche convenience case that I don't want to bake content assumptions around it.
"""
from datetime import datetime
import os
import time
from PIL import Image
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from tqdm import tqdm
# pyright: reportUnknownMemberType=false
# Settings (make cmd args if changing often).
HOST = "https://talktomehuman.com"
PARENT_FOLDER = "./ttmh-screenshots/"
FOLDER = "ttmh-" + datetime.now().strftime("%y%m%d-%H%M%S")
PAGES = [
"/",
"/changelog",
"/press",
"/login",
]
PRESETS: dict[str, tuple[int, int]] = {
"desktop": (1024, 768),
"phone": (375, 667),
}
SCROLL_ELEMENT_CSS_SELECTOR = ".overflow-y-scroll"
SCROLL_OVERLAP = 0 # px. using 0 b/c stitching together after
SCREENSHOTS_PER_PAGE_LIMIT = 50 # safety fallback
def main() -> None:
folder = os.path.join(PARENT_FOLDER, FOLDER)
os.makedirs(folder)
print("Saving screenshots to", folder)
chrome_options = Options()
chrome_options.add_argument("--window-size=500,500") # will resize anyway
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
for page in tqdm(PAGES):
url = HOST + page
driver.get(url)
# If there's predictable structure on the page, wait for an element to be
# available (due to React adding true content after page "load"):
#
# https://selenium-python.readthedocs.io/waits.html#explicit-waits
#
# For now, because pages have no explicit ID's elements and the structure varies
# per page, just blindly sleep.
time.sleep(1)
scroll_to = 0
for i, (name, (w, h)) in enumerate(PRESETS.items()):
driver.set_window_size(w, h)
# Try to figure out height.
# Options for locating elements:
# https://selenium-python.readthedocs.io/locating-elements.html
try:
driver.find_element(By.CSS_SELECTOR, SCROLL_ELEMENT_CSS_SELECTOR)
res = driver.execute_script( # type: ignore
f"return document.querySelector('{SCROLL_ELEMENT_CSS_SELECTOR}').scrollHeight"
)
if isinstance(res, int):
# save height
scroll_to = res
else:
print(
f"Got non-int scrollHeight for CSS selector {SCROLL_ELEMENT_CSS_SELECTOR}: {res} ({type(res)})" # type: ignore
)
except NoSuchElementException:
print(
f"CSS selector {SCROLL_ELEMENT_CSS_SELECTOR} returned no elements. Taking single screenshot."
)
# NOTE: Haven't factored SCROLL_OVERLAP into stitching.
scroll_by = h - SCROLL_OVERLAP
# On first load, scroll to bottom, pausing at each stop. Why? For
# elements/animations that reveal/play on scroll: (a) they won't always
# register screen overlap and trigger starting if scrolling directly to
# bottom; (b) they also may not register if scrolling too quickly.
if i == 0 and scroll_to != 0:
for target in range(0, scroll_to, scroll_by):
driver.execute_script(
f"document.querySelector('{SCROLL_ELEMENT_CSS_SELECTOR}').scrollTo(0, {target})"
)
# weirdly, if sleeping at end, things aren't fully revealed.
time.sleep(0.5)
# Always scroll back to top.
driver.execute_script(
f"document.querySelector('{SCROLL_ELEMENT_CSS_SELECTOR}').scrollTo(0, 0)"
)
# Grab screens
visible, n = h, 1
paths: list[str] = []
page_cleaned = page.replace("/", "-")
page_path = "-home" if page_cleaned == "-" else page_cleaned
while True:
# determine filename and save screenshot
filename = name + page_path + f"-{n}.png"
path = os.path.join(folder, filename)
driver.save_screenshot(path)
paths.append(path)
if visible >= scroll_to or n >= SCREENSHOTS_PER_PAGE_LIMIT:
break
# scroll
driver.execute_script(
f"document.querySelector('{SCROLL_ELEMENT_CSS_SELECTOR}').scrollBy(0, {scroll_by})"
)
visible += scroll_by
n += 1
# Stich them together. NOTE: assumes all screenshots exactly (w, h) size.
if len(paths) > 1:
imgs = [Image.open(p) for p in paths]
stitched_img = Image.new("RGB", (w, scroll_to))
y_offset = 0
# Do all but last img (which likely has overlap)
for img in imgs[:-1]:
stitched_img.paste(img, (0, y_offset))
y_offset += img.height
# Crop last img just to novel part.
captured = h * len(paths)
overlap = captured - scroll_to
cropped_final = imgs[-1].crop((0, overlap, w, h))
stitched_img.paste(cropped_final, (0, y_offset))
# Save
stitched_filename = name + page_path + "-stitched.png"
stitched_path = os.path.join(folder, stitched_filename)
stitched_img.save(stitched_path)
driver.quit()
if __name__ == "__main__":
main()Addendum: Related Work
After finishing this, I realized there might be services online that will screenshot your webpage for you.09
Happily, the ones I found both:
- Want you to pay
- Don’t work with my inner-scrolling-element page quirks described above
So, for my particular small-scale use case, it was worth it to just have a small script I can run.
See You Next Time
That’s all for this devlog entry. Until we meet again, dear reader. Oh, and please do check out Talk to Me Human if you haven’t!
Footnotes
I’ve heard this is true with woodworking and metalworking as well—that make your own tools is the most satisfying way to spend time. ↩︎
Originally I was looking up how to dynamically compute how much of an element is visible on screen. This seemed quite complicated and wouldn’t even work for my use case. But now I’m wondering why I didn’t just use the containing element’s height? Regardless, we’ll cross this bridge later if we ever need to. ↩︎
There was even an NLP dataset webpage that had ultra slow reveals on scrolling. ↩︎
I wanted to make this paragraph appear on scroll but it wasn’t worth installing another framework on my website. Sorry. ↩︎
I will save you Googling this extremely obscure reference that I also had to Google: Brendan Eich created JavaScript. ↩︎
I joke here, but actually props to Google engineers for preventing feature creep. It probably matters less whether you’re drawing the exact right lines in the sand, but that you’re able to draw them at all and stand by them. ↩︎
No joke. Like,
min(2,5) == 2. The minimum of two numbers. Literally not in the language (well, the stdlib). They added it in 2023, a mere 14 years after the language’s release. ↩︎As with most JavaScript build system-y things, if you know what you’re doing, this is probably trivial. E.g., maybe it’s just defining a new template and changing a few lines of Vite config. But, as with most JavaScript things, there are so many layers of which you can be an expert, that if you’re perpetually a newcomer like me, you’re not an expert in anything. So figuring out any new config takes hours. ↩︎
Reminds me of how I’d work on a research project for months before deciding to look up related work. Some things never change. ↩︎

{kind=link}